

【把長條圖畫成折線圖!】 (就這樣而已~)
對非本科的而言,這肯定又是一個乍看即令人敬而遠之的專有名詞,若再直接搭配它給的各種機率密度函數,幾乎是讓人一眼就放棄瞭解,但其實它的概念非常單純。
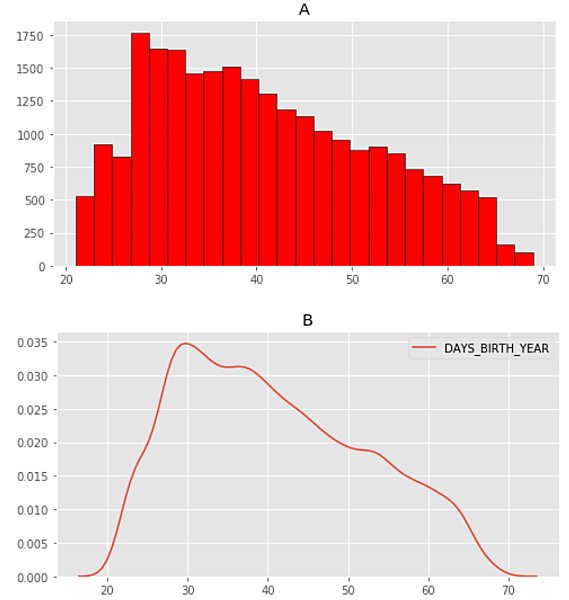
更簡單一點來說,當我只是把A圖改畫成B圖,我就可以說:「我作了核密度估計。」或是推推眼鏡說:「沒什麼,KDE一下而已。」而把A畫成B這工作之簡單,甚至只是軟體中改個呈現方式(長條圖改折線圖)、或語法中改個參數(hist改成kdeplot)這樣罷了。
也因此,如果能懂長條圖在幹嘛,也能看著圖解釋其中意思,那當它變成折線圖時,有什麼好突然變得不懂的呢?
會不懂的原因發生在,過往我們學習過程,面對這艱澀難看超有距離感的專有名詞長相先不談,首先面對到的都是機率密度函數,在我根本還不知道它只是想做到「把長條圖畫成折線圖」這件事之前,告訴我機率密度函數,到底是要幹嘛?
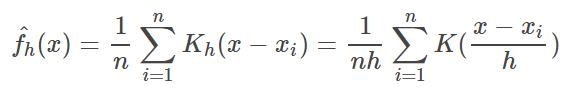
這東西要教人,講者要先告訴大家:「我現在要做一件事:把長條圖改畫成折線圖。」然後千萬先不要提到「核密度估計」這麼令人絕望的五個字,也都先不要秀出機率密度函數,我相信台下能繼續聽下去的人肯定大增。
困難的點發生在,怎麼畫的?
如果我人工要畫,我該怎麼畫?
長條圖轉換成折線圖有一個很大的定義落差,在於:
長條圖是離散型,每根長條有自己的定義,例如20~29歲有多少人、30~39歲有多少人…,但這已經把20~29歲的人看成是同一群人,同一群沒有年齡差異的人;但變成折線圖時並不是,折線圖是連續型的概念,它根據你給的20~29歲有多少人、30~39歲有多少人…,去「估計」每個連續數值:20歲有多少人、20.1歲有多少人、20.2歲有多少人(甚至切分到無窮個小數點)……進而去畫出連續不中斷的折線圖。
其實直到上面這段敘述,都還不難理解,就算一時之間沒有理解,相信也是卡在連續型無窮細分的這個哲學議題裡,最難的是:該怎麼估計?如果20~29歲有10人、30~39歲有16人,那我估計30歲的人可能有13人,這方式OK嗎?
於是有了各種估計方式:Gaussian、Triweight、Epanechnikov……,然後各自有各自的機率密度函數(就是你給了它一個歲數,可以是38.8787歲,函數會告訴你估計起來有幾個人),這才是困難點。
但現在這個時代,我們真有必要去深入了解這些估計方式的機率密度函數,才能使用KDE嗎?不瞭解就會被人說不求甚解連用都不能用嗎?問我答案絕對是否定的。
我覺得啦,要鑽研理論、要欣賞機率密度函數之美、要熱愛微積分,那是一回事,但拿來實用作圖等等的,直接參數改了就知道現在用的是哪個估計方式,這完全是實務領域的另外一回事。
在實務領域,長條圖解釋、折線圖解釋,前後幾乎不會有差異,一樣是在談幾歲的人有幾個、整張圖的趨勢如何,只是前者是一群一群看、後者是某條平滑線直接看。
縱使折線圖上是估計的點,我們也並不會真的去討論這樣的「估計」準不準、也不會去討論該用哪種估計方式,因為我們看折線圖通常是看趨勢,而不是去看折線圖當中的某一個點!
既然如此,何必要浪費時間執著在懂不懂有哪些估計方式和它實際函數長相?
話再說回來,實務上到底為什麼要把長條圖畫成折線圖?
真的沒什麼,就單純視覺上比較好看罷了!
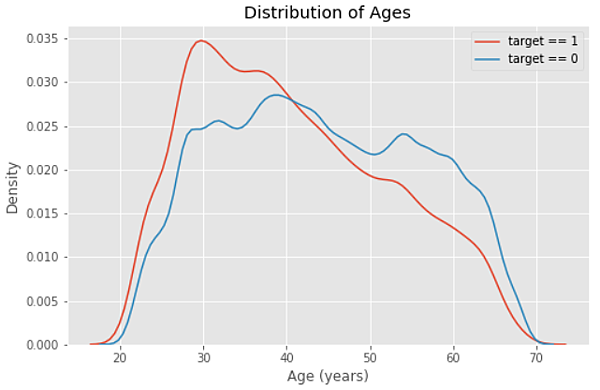
可以想像當現在是兩種顏色的長條圖比較,如果改成兩種顏色的折線圖比較,是不是折線圖會更清楚?
上圖是不是一眼就能看出紅線那一群的人偏年輕?很清楚嘛,比長條圖清楚太多了。
而平常需要換成折線圖,也只是因為「清楚」這個原因,而不會去追究哪個歲數要有多麼「精準」的預估人數。
總結一下,概念上很單純的「將長條圖改畫成折線圖」這個動作,有個專有名詞叫做【核密度估計(Kernel Density Estimation, KDE)】。
循序漸進,由淺入深,要難可以很難,要深究可以很深究,但實務運用上我們往往不需真得學到這麼難。也不需要講出專有名詞好像彰顯自己很懂很了不起。
「這個長條圖可以改成折線圖嗎?」
「這張圖可以改用核密度估計嗎?」
不覺得在職場上講出類似後面那句話的人,
故意要把一個很簡單的東西講得好像很深奧的人,
真的很讓人討厭嘛……