在於將資料【處理成應用上想看到的正確】
從交易資料中……
找到「有買筆電」的人:簡單
找到「沒買防窺片」的人:簡單
但找「買完筆電後一週內沒買防窺片」的人呢?
這就有點難度囉……
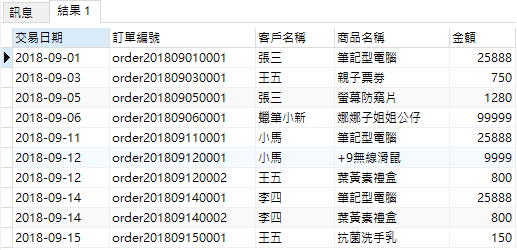
舉例來說,圖片是會員交易資料,裡面包括:交易日期、客戶名稱、商品名稱、商品金額等等相關資訊。
現在需要如下資料,好準備之後作分析及行銷:
1. 買過筆電但沒買過防窺片的人
2. 已經超過1個月沒有消費的人
3. 只在網站消費過一次的人
原始資料並無法直接給出這三種資料,必須透過某些邏輯判斷,即是「資料採礦」的過程:
1. 找出買過筆電的人,找出沒有買過防窺片的人,做交集。
2. 找出每個人最後一次的消費日期,看誰的最後消費日期距今超過1個月。
3. 計算出每個人消費次數,找出次數只有1的人。(同天的不同次交易,當作1次嗎?是目標嗎?)
透過上述可知,每個人的每次消費,都是正確且重要的資料,但並不需要呈現每一筆資料,卻又必須拿到並使用每一筆資料,才有辦法得到目標。
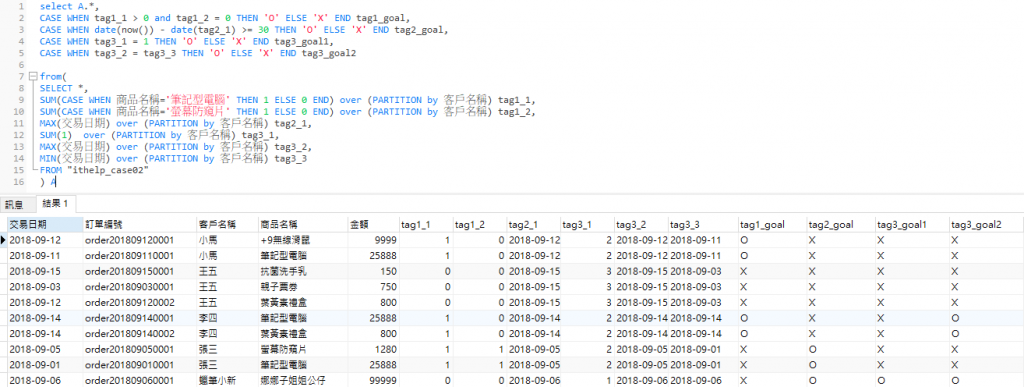
最終我們將這群人做出了3(+1)種分類,如圖透過資料採礦製作出【O,X】的欄位,至此,即可直接使用這欄位找出目標對象。
【資料採礦】的初級、中級、高級怎麼分呢?
舉例來說,如上的3類製作,都屬於初級,或使用Excel樞紐分析表即可處理的,最簡單的如:每月營收、每人總消費金額等等。
當條件越多,所需撰寫語法越多,甚至搭配統計值,所耗工時越長,則難度會漸漸傾向中級甚至高級。例如:「漲停板隔天,也漲停板的機率?」屬於初級,「連續兩個月的波動介於正負10%間,則未來半年先漲10%的機率是多少?先跌10%的機率多少?半年不漲不跌介於正負10%間的機率多少?」這就屬於中高級採礦的範疇了。
資料採礦可能乍看會覺得,嗯?不就肉眼看一看、Excel樞紐分析表拉一拉就好,有什麼了不起的?如果現在只有如圖片中十幾筆資料,確實人工處理就好,但當現在若資料有幾十萬筆……甚至如健保局資料有十幾億筆,千萬不要浪費生命用人工方式去處理。
尤其高級採礦的技術,放眼業界,能達到這樣專業水準的專家也已經不多了。
請儘管相信專業,交給專業。