#案件實例系列文
資料採礦,我們並不需要呈現每一筆資料,卻又必須拿到並使用每一筆資料。
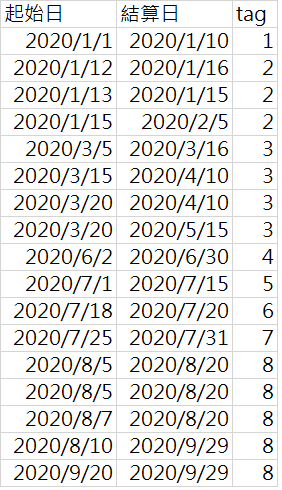
在這次的案例中,想了解一個人在犯罪後若被判處緩起訴,則距離下次再犯,間隔多少的天數?緩起訴究竟有沒有用?(可惜這篇文章不會告訴你結果,這是客戶的研究內容,不好這邊公開說。)
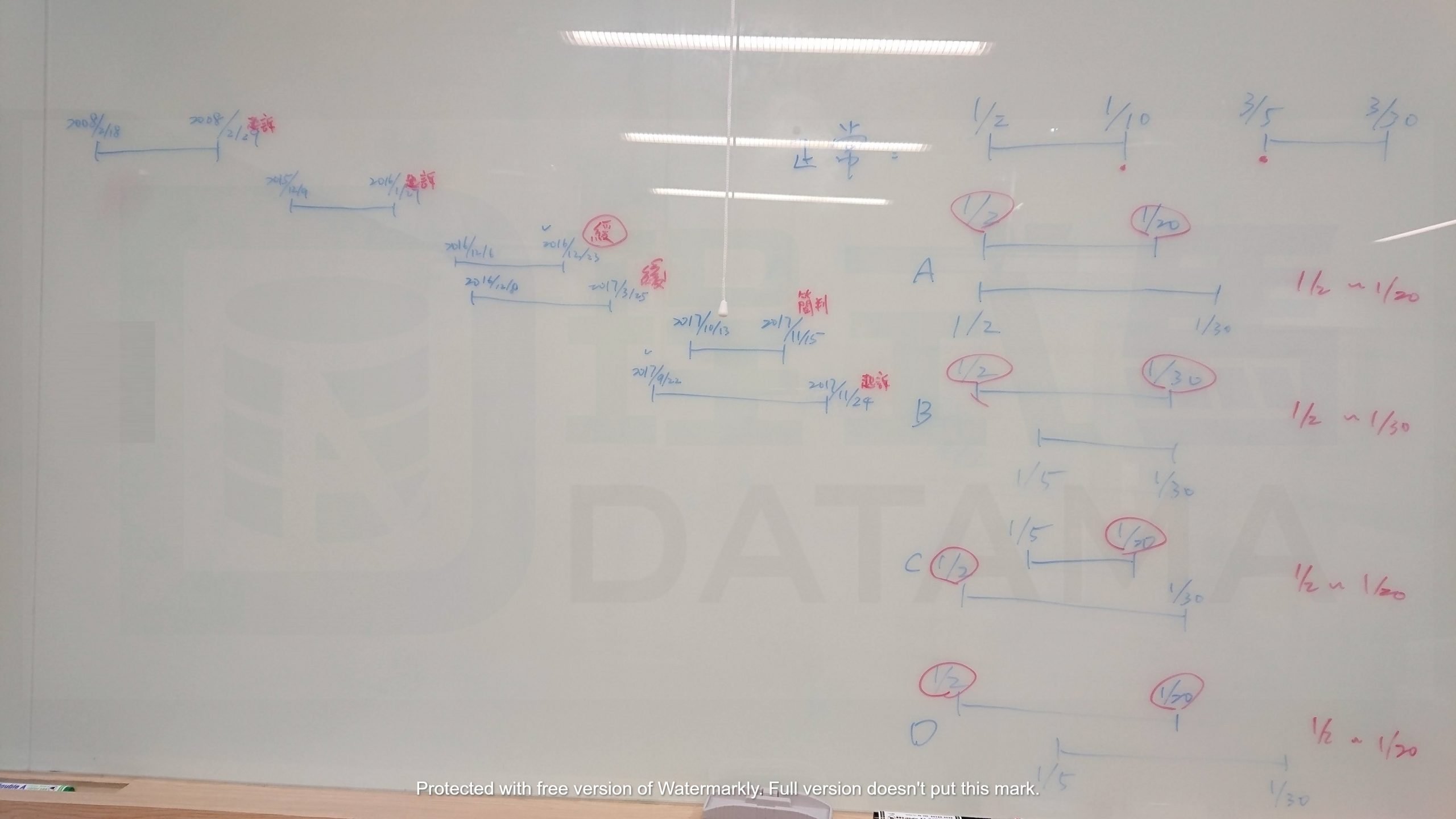
然而,要計算「天數間隔」,意味著要有一個「結算日」,下一次則要有一個「起始日」,才能計算這兩個日期間的天數差。問題來了!現在這人於差不多相同的一段期間內,並不是只有一筆犯罪記錄,十幾二十筆都有可能,且此人的每一筆資料都各自有「起始日」與「結算日」,日期間彼此交錯重疊……
處理上,有交疊到的資料,必須合併成一群,並將沒有交疊到的資料分開成另一群,換言之,「天數間隔」要計算的是這群資料的「結算日」,與下一群資料的「起始日」,之間的差。
該怎麼透過語法去……
1. 將不同群切開,不同群將不再有交疊的日期區間。
2. 定義出相同群的「起始日」和「結算日」。
「才十幾二十筆,我不能自己用眼睛看嗎?」
「但總資料筆數有120萬筆啊…你可能得準備一下眼藥水…」
這已經是資料採礦中級以上的題目,SQL熟手都不見得能第一時間作出,我將同樣概念的日期資料,製作一份如下dropbox網址,有興趣的不妨挑戰看看,在只取得起始日和結算日的狀況下,如何把tag欄位(如檔案有1~8群)給寫出來呢?